请注意random库与chrono库均是C++11。
1 |
|
请注意random库与chrono库均是C++11。
1 |
|
一含有特定二进制位数 N 的容器,相当于 bool 数组,但压缩内存至每一个二进制位。
bitset<N> bset,其中 N 为字面常量,表示 bitset 中的二进制位个数。如 bitset<10> bset;
bitset(unsigned long val) 用 val 构造一个对应的 bitset (至 C++11 前)
bitset(unsigned long long val) 用 val 构造一个对应的 bitset (自 C++11 始)
bitset(string val) 用 val 构造一个对应的 bitset
bool operator[] 获取特定二进制位的值
bool test(pos) 获取特定二进制位的值,但有越界检查:如果越界,抛出 std::out_of_range 异常。
基本与 map 相同,但除去了 operator[], 因为其特点是相同 key 的值在 multimap 中可以多个存在。需要强调的,与 map 有明显不同的常用方法:
iterator insert(value) 插入键值对,返回插入后该元素的迭代器
size_type erase(key) 删除所有关键字与 key 相等的键值对,返回删除的元素个数
void erase(iterator pos) 删除对应位置元素
size_type count(key) 统计关键字为 key 的元素个数
iterator find(key) 查找关键字与 key 相等的键值对,返回对应位置的迭代器。如果不存在则返回 end() 。如果有多个关键字与 key 相等的键值对,返回的迭代器指向哪一个不定。
pair<iterator, iterator> equal_range(key) 查找关键字与 key 相等的键值对,返回迭代器对,描述与 key 相等的键值对的区间 [first, last) 。
1 |
|
1 | output |
与上述 multimap 的用法基本相同,只是每个元素只有一个值 key,而没有对应的 value。
保存 $0 \sim n-1$ 的全排列,含义是把所有后缀按字典序排序后,后缀在原串中的位置。$suffix(sa[i]) < suffix(sa[i + 1])$
$sa[,]$ 记录位置,即“排第i的后缀是谁”。
保存 $0 \sim n-1$ 的全排列,$rk[i]$ 的含义是 $suffix(i)$ 在所有后缀中按字典序排序的名次。
$rk[,]$ 记录排名,即“第以第i个字符起始的后缀子串在所有后缀子串中排第几”。
$sa[,]$ 与 $rk[,]$ 是一一对应的关系,且互为逆运算。于是
可用 $rk[,]$ 推导 $sa[,]$: for (int i = 0; i < n; ++i) sa[rk[i]] = i;
可用 $sa[,]$ 推导 $rk[,]$: for (int i = 0; i < n; ++i) rk[sa[i]] = i;
LCP 即 Longest Common Prefix,最长公共前缀。
记 $LCP(i, j)$ 为 $suffix(sa[i])$ 与 $suffix(sa[j])$ 的最长公共前缀长度,即排序后第 $i$ 个后缀与第 $j$ 个后缀的最长公共前缀长度
若 $0 \lt i \lt j \lt k \le n-1$,则 $LCP(i, k) = min{LCP(i, j),,LCP(j, k)}$。
证明:
设 $p=min{LCP(i, j), LCP(j, k)}$ ,则 $LCP(i, j) \ge p ,;LCP(j, k) \ge p$。
又设 $suffix(sa[i])=u,;suffix(sa[j])=v,;suffix(sa[k])=w$ ①。
我们记 $a=_{len}b$表示字符串 $a$ 长度为 $len$ 的前缀与字符串 $b$ 的长度为 $len$ 的前缀相等。
则由 $u={LCP(i,j)}v$ 可得 $u={p}v, ; v=_{p}w$ 。
于是可得 $u=_{p}w$。即 $LCP(i, k) \ge p = min{LCP(i, j),,LCP(j, k)}$。
现在我们再证 $LCP(i,k) \gt p$ 是不可能的。
又设存在一个 $q \gt p$,$LCP(i, k) = q$。
则可得 $u[i] = w[i]$ 对任意 $i \in [1, q]$ 均成立。由于 $q \gt p$,所以上式中的一个是 $u[p+1] = w[p+1]$。
由 ① 得 $u[p+1] \leq v[p+1] \leq w[p+1]$。结合上一行得 $u[p+1]=v[p+1]=w[p+1]$。
而 $p=min{LCP(i, j), LCP(j, k)}$,即 $u[p+1] \neq v[p+1]$ 或 $v[p+1] \ne w[p+1]$。
出现矛盾,故不存在 $q$ ,使得假设 $LCP(i, k) = q \gt p$ 成立。即得 $LCP(i, k) \le p$。
故得 $LCP(i, k) \ge p$ 且 $LCP(i, k) \le p$。
最后 $LCP(i, k) = min{LCP(i, j), LCP(j, k)}$。
若 $i \lt j$ 则 $LCP(i, j) = min{LCP(k - 1, k)},;i \lt k \le j$
证明:由 LCP Lemma 与数学归纳法可得。
$height[,]$ 是一个辅助数组,和最长公共前缀 (LCP) 相关。
令 $height[i]=LCP(i-1,i),;1 \lt i \le n$ ,即 $suffix(sa[i-1])$ 与 $suffix(sa[i])$ 的最长公共前缀长度。
为了描述方便,记 $h[i]$ 为 $height[rank[i]]$ ,即后缀 $suffix(i)$ 与 $suffix(sa[rank[i]-1])$ 的LCP长度。
有一个很重要的性质可以让我们在 $O(N)$ 的时间内求得 $height[]$ 数组:$h[i] \ge h[i-1] - 1$ 。
证明:
设 $suffix(k)$ 是排在 $suffix(i-1)$ 前一名的后缀,则它们的LCP长度为 $h[i-1]$。两者都去掉第一个字符,得到 $suffix(k+1)$ 与 $suffix(i)$ 。
① 若 $h[i-1] \le 1$ ,即 $h[i-1]-1 \le 0$ ,则 $h[i] \ge h[i-1] - 1$ 显然成立。
② 若 $h[i-1] \gt 1$ ,则在上面去掉第一个字符的过程中是去掉的两者LCP中的第一个字符,那么 $suffix(k+1)$ 与 $suffix(i)$ 的LCP长度就至少为 $h[i] \ge [h-1]-1$ 。
故 $h[i] \ge h[i-1]-1$ 得证。
个人模板,供参考。设字符串长度为 $N$,则下面代码求三数组的复杂度为 $O(N;logN)$。
1 |
|
https://www.cnblogs.com/ECJTUACM-873284962/p/6618870.html
https://blog.csdn.net/qq_37774171/article/details/81776029
从上两文中做了一些参考,但部分证明感觉并不浅显易懂,在加以个人理解后最后形成此文。
堆是一种数据结构,而priority_queue (优先队列)是一个基于二叉堆的STL容器。
堆有很多种类,但以下提及的堆均为二叉堆。
以下是一个例子。将新元素20插入二叉堆:
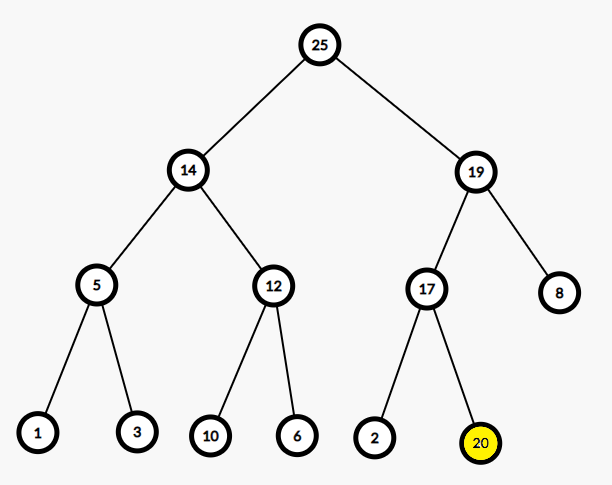
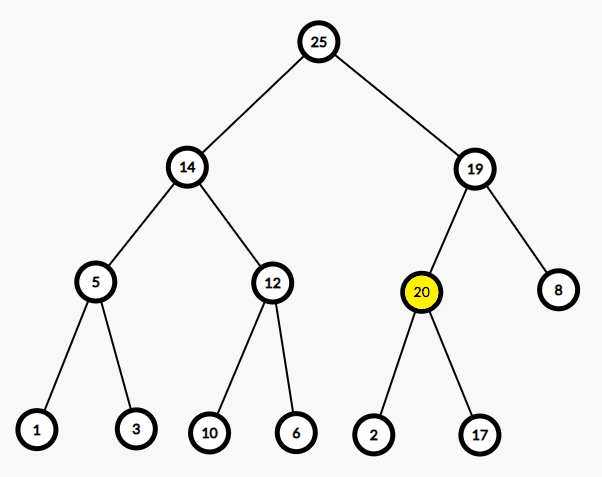
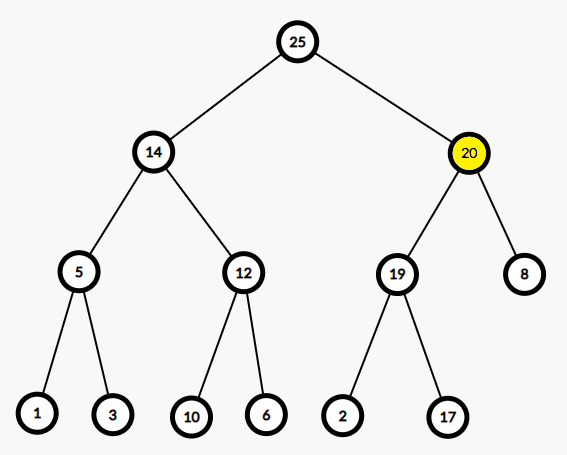
所以对一个二叉堆,有3种基本操作:
插入:将 val 插入堆。
取堆顶:查看堆顶元素值。(即整个堆中最大或最小值)
出堆:将堆顶元素出堆。
Update your browser to view this website correctly. Update my browser now